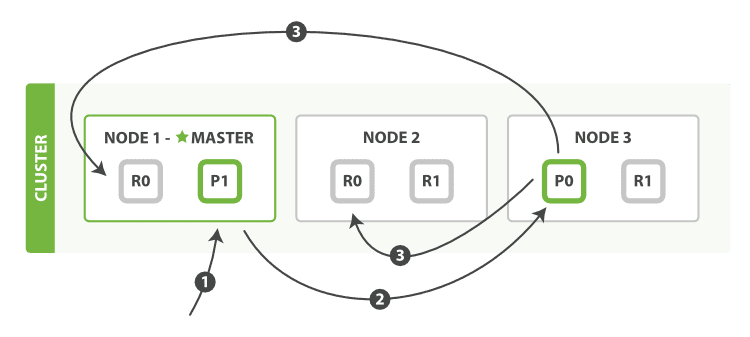
MySQL数据一致性的绝杀利器

宣传部部长
2024-04-23 23:38

欢迎各位阅读本篇,MySQL 最流行的关系型数据库管理系统,在 WEB 应用方面MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一。本篇文章讲述了关于新型MySQL集群架构剖析。

1. 何谓Galera Cluster
何谓Galera Cluster?就是集成了Galera插件的MySQL集群,是一种新型的,数据不共享的,高度冗余的高可用方案,目前Galera Cluster有两个版本,分别是Percona Xtradb Cluster及MariaDB Cluster,都是基于Galera的,所以这里都统称为Galera Cluster了,因为Galera本身是具有多主特性的,所以Galera Cluster也就是multi-master的集群架构,如图1所示:

图1 Galera Cluster架构
图1中有三个实例,组成了一个集群,而这三个节点与普通的主从架构不同,它们都可以作为主节点,三个节点是对等的,这种一般称为multi-master架构,当有客户端要写入或者读取数据时,随便连接哪个实例都是一样的,读到的数据是相同的,写入某一个节点之后,集群自己会将新数据同步到其它节点上面,这种架构不共享任何数据,是一种高冗余架构。
一般的使用方法是,在这个集群上面,再搭建一个中间层,这个中间层的功能包括建立连接、管理连接池,负责使三个实例的负载基本平衡,负责在客户端与实例的连接断开之后重连,也可以负责读写分离(在机器性能不同的情况下可以做这样的优化)等等,使用这个中间层之后,由于这三个实例的架构在客户端方面是透明的,客户端只需要指定这个集群的数据源地址,连接到中间层即可,中间层会负责客户端与服务器实例连接的传递工作,由于这个架构支持多点写入,所以完全避免了主从复制经常出现的数据不一致的问题,从而可以做到主从读写切换的高度优雅,在不影响用户的情况下,离线维护等工作,MySQL的高可用,从此开始,非常完美。
2. 为什么需要Galera Cluster
MySQL在互联网时代,可谓是深受世人瞩目的。给社会创造了无限价值,随之而来的是,在MySQL基础之上,产生了形形色色的使用方法、架构及周边产品。本文所关注的是架构,在这方面,已经有很多成熟的被人熟知的产品,比如MHA、MMM等传统组织架构,而这些架构是每个需要数据库高可用服务方案的入门必备选型。
不幸的是,传统架构的使用,一直被人们所诟病,因为MySQL的主从模式,天生的不能完全保证数据一致,很多大公司会花很大人力物力去解决这个问题,而效果却一般,可以说,只能是通过牺牲性能,来获得数据一致性,但也只是在降低数据不一致性的可能性而已。所以现在就急需一种新型架构,从根本上解决这样的问题,天生的摆脱掉主从复制模式这样的“美中不足”之处了。
幸运的是,MySQL的福音来了,Galera Cluster就是我们需要的——从此变得完美的架构。
相比传统的主从复制架构,Galera Cluster解决的最核心问题是,在三个实例(节点)之间,它们的关系是对等的,multi-master架构的,在多节点同时写入的时候,能够保证整个集群数据的一致性,完整性与正确性。
在传统MySQL的使用过程中,也不难实现一种multi-master架构,但是一般需要上层应用来配合,比如先要约定每个表必须要有自增列,并且如果是2个节点的情况下,一个节点只能写偶数的值,而另一个节点只能写奇数的值,同时2个节点之间互相做复制,因为2个节点写入的东西不同,所以复制不会冲突,在这种约定之下,可以基本实现多master的架构,也可以保证数据的完整性与一致性。但这种方式使用起来还是有限制,同时还会出现复制延迟,并且不具有扩展性,不是真正意义上的集群。
3. Galera Cluster如何解决问题
3.1 Galera的引入现在已经知道,Galera Cluster是MySQL封装了具有高一致性,支持多点写入的同步通信模块Galera而做的,它是建立在MySQL同步基础之上的,使用Galera Cluster时,应用程序可以直接读、写某个节点的最新数据,并且可以在不影响应用程序读写的情况下,下线某个节点,因为支持多点写入,使得Failover变得非常简单。
所有的Galera Cluster,都是对Galera所提供的接口API做了封装,这些API为上层提供了丰富的状态信息及回调函数,通过这些回调函数,做到了真正的多主集群,多点写入及同步复制,这些API被称作是Write-Set Replication API,简称为wsrep API。
通过这些API,Galera Cluster提供了基于验证的复制,是一种乐观的同步复制机制,一个将要被复制的事务(称为写集),不仅包括被修改的数据库行,还包括了这个事务产生的所有Binlog,每一个节点在复制事务时,都会拿这些写集与正在APPLY队列的写集做比对,如果没有冲突的话,这个事务就可以继续提交,或者是APPLY,这个时候,这个事务就被认为是提交了,然后在数据库层面,还需要继续做事务上的提交操作。
这种方式的复制,也被称为是虚拟同步复制,实际上是一种逻辑上的同步,因为每个节点的写入和提交操作还是独立的,更准确的说是异步的,Galera Cluster是建立在一种乐观复制的基础上的,假设集群中的每个节点都是同步的,那么加上在写入时,都会做验证,那么理论上是不会出现不一致的,当然也不能这么乐观,如果出现不一致了,比如主库(相对)插入成功,而从库则出现主键冲突,那说明此时数据库已经不一致,这种时候Galera Cluster采取的方式是将出现不一致数据的节点踢出集群,其实是自己shutdown了。
而通过使用Galera,它在里面通过判断键值的冲突方式实现了真正意义上的multi-master,Galera Cluster在MySQL生态中,在高可用方面实现了非常重要的提升,目前Galera Cluster具备的功能包括如下几个方面:
多主架构:真正的多点读写的集群,在任何时候读写数据,都是最新的。
同步复制:集群不同节点之间数据同步,没有延迟,在数据库挂掉之后,数据不会丢失。
并发复制:从节点在APPLY数据时,支持并行执行,有更好的性能表现。
故障切换:在出现数据库故障时,因为支持多点写入,切的非常容易。
热插拔:在服务期间,如果数据库挂了,只要监控程序发现的够快,不可服务时间就会非常少。在节点故障期间,节点本身对集群的影响非常小。
自动节点克隆:在新增节点,或者停机维护时,增量数据或者基础数据不需要人工手动备份提供,Galera Cluster会自动拉取在线节点数据,最终集群会变为一致。
对应用透明:集群的维护,对应用程序是透明的,几乎感觉不到。 以上几点,足以说明Galera Cluster是一个既稳健,又在数据一致性、完整性及高性能方面有出色表现的高可用解决方案。
不过在运维过程中,有些技术特点还是需要注意的,这样才能做到知此知彼,百战百胜,因为现在MySQL主从结构的集群已经都是被大家所熟知的了,而Galera Cluster是一个新的技术,是一个在不断成熟的技术,所以很多想了解这个技术的同学,能够得到的资料很少,除了官方的手册之外,基本没有一些讲得深入的,用来传道授业解惑的运维资料,这无疑为很多同学设置了不低的门槛,最终有很多人因为一些特性,导致最终放弃了Galera Cluster的选择。
目前熟知的一些特性,或者在运维中需要注意的一些特性,有以下几个方面:
Galera Cluster写集内容:Galera Cluster复制的方式,还是基于Binlog的,这个问题,也是一直被人纠结的,因为目前Percona Xtradb Cluster所实现的版本中,在将Binlog关掉之后,还是可以使用的,这误导了很多人,其实关掉之后,只是不落地了,表象上看上去是没有使用Binlog了,实际上在内部还是悄悄的打开了的。除此之外,写集中还包括了事务影响的所有行的主键,所有主键组成了写集的KEY,而Binlog组成了写集的DATA,这样一个KEY-DATA就是写集。KEY和DATA分别具有不同的作用的,KEY是用来验证的,验证与其它事务没有冲突,而DATA是用来在验证通过之后,做APPLY的。
Galera Cluster的并发控制:现在都已经知道,Galera Cluster可以实现集群中,数据的高度一致性,并且在每个节点上,生成的Binlog顺序都是一样的,这与Galera内部,实现的并发控制机制是分不开的。所有的上层到下层的同步、复制、执行、提交都是通过并发控制机制来管理的。这样才能保证上层的逻辑性,下层数据的完整性等。

图2 galera原理图
图2是从官方手册中截取的,从图中可以大概看出,从事务执行开始,到本地执行,再到写集发送,再到写集验证,再到写集提交的整个过程,以及从节点(相对)收到写集之后,所做的写集验证、写集APPLY及写集提交操作,通过对比这个图,可以很好的理解每一个阶段的意义及性能等,下面就每一个阶段以及其并发控制行为做一个简单的介绍:
a. 本地执行:这个阶段,是事务执行的最初阶段,可以说,这个阶段的执行过程,与单点MySQL执行没什么区别,并发控制当然就是数据库的并发控制了,而不是Galera Cluster的并发控制了。
b. 写集发送:在执行完之后,就到了提交阶段,提交之前首先将产生的写集广播出去,而为了保证全局数据的一致性,在写集发送时,需要串行,这个就属于Galera Cluster并发控制的一部分了。
c. 写集验证:这个阶段,就是我们通常说的Galera Cluster的验证了,验证是将当前的事务,与本地写集验证缓存集来做验证,通过比对写集中被影响的数据库KEYS,来发现有没有相同的,来确定是不是可以验证通过,那么这个过程,也是串行的。
d. 写集提交:这个阶段,是一个事务执行时的最后一个阶段了,验证完成之后,就可以进入提交阶段了,因为些时已经执行完了的,而提交操作的并发控制,是可以通过参数来控制其行为的,即参数repl.commit_order,如果设置为3,表示提交就是串行的了,而这也是本人所推荐的(默认值)的一种设置,因为这样的结果是,集群中不同节点产生的Binlog是完全一样的,运维中带来了不少好处和方便。其它值的解释,以后有机会再做讲解。
e. 写集APPLY:这个阶段,与上面的几个在流程上不太一样,这个阶段是从节点做的事情,从节点只包括两个阶段,即写集验证和写集APPLY,写集APPLY的并发控制,是与参数wsrep_slave_threads有关系的,本身在验证之后,确定了相互的依赖关系之后,如果确定没有关系的,就可以并行了,而并行度,就是参数wsrep_slave_threads的事情了。wsrep_slave_threads可以参照参数wsrep_cert_deps_distance来设置。
3.2 流量控制在PXC中,有一个参数叫fc_limit,它的全名其实是叫flow control limit,顾名思义,是流量控制大小限制的意思,它的作用是什么呢?
如果一套集群中,某个节点,或者某几个节点的硬件资源比较差,或者由于节点压力大,导致复制效率低下,等等各种原因,导致的结果是,从节点APPLY时,非常慢,也就是说,主库在一秒钟之内做的操作,从库有可能会用2秒才能完成,那么这种情况下,就会导致从节点执行任务的堆积,接收队列的堆积。
假设从节点真的堆积了,那么Galera会让它一直堆积下去么?这样延迟会越来越严重,这样Galera Cluster就变成一个主从架构的集群了,已经失去了强一致状态的属性了,那么很明显,Galera是不会让这种事情发生的,那么此时,就说回到开头提到的参数了,gcs.fc_limit,这个参数是在MySQL参数wsrep_provider_options中来配置的,这个参数是Galera的一个参数集合,有关于Flow Control的,还包括gcs.fc_factor,这两个参数的意义是,当从节点堆积的事务数量超过gcs.fc_limit的值时,从节点就发起一个Flow Control,而当从节点堆积的事务数小于gcs.fc_limit * gcs.fc_factor时,发起Flow Control的从节点再发起一个解除的消息,让整个集群再恢复。
但我们一般所关心的,就是如何解决,下面有几个一般所采用的方法:
发送FC消息的节点,硬件有可能出现问题了,比如IO写不进去,很慢,CPU异常高等
发送FC消息的节点,本身数据库压力太高,比如当前节点承载太多的读,导致机器Load高,IO压力大等等。
发送FC消息的节点,硬件压力都没有太大问题,但做得比较慢,一般原因是主库并发高,但从节点的并发跟不上主库,那么此时可能需要观察这两个节点的并发度大小,可以参考状态参数wsrep_cert_deps_distance的值,来调整从节点的wsrep_slave_threads,此时应该是可以解决或者缓解的,这个问题可以这样去理解,假设集群每个节点的硬件资源都是相当的,那么主库可以执行完,从库为什么做不过来?那么一般思路就是像处理主从复制的延迟问题一样。
检查存不存在没有主键的表,因为Galera的复制是行模式的,所以如果存在这样的表时,主节点是通过语句来修改的,比如一个更新语句,更新了全表,而从节点收到之后,就会针对每一行的Binlog做一次全表扫描,这样导致这个事务在从节点执行,比在主节点执行慢十倍,或者百倍,从而导致从节点堆积进而产生FC。
可以看出,其实这些方法,都是用来解决主从复制延迟的方法,没什么两样,在了解Flow Control的情况下,解决它并不是难事儿。
3.3 有很多坑?有很多同学,在使用过Galera Cluster之后,发现很多问题,最大的比如DDL的执行,大事务等,从而导致服务的不友好,这也是导致很多人放弃的原因。
DDL执行卡死传说:使用过的同学可能知道,在Galera Cluster中执行一个大的改表操作,会导致整个集群在一段时间内,是完全写入不了任何事务的,都卡死在那里,这个情况确实很严重,导致线上完全不可服务了,原因还是并发控制,因为提交操作设置为串行的,DDL执行是一个提交的过程,那么串行执行改表,当然执行多久,就卡多久,直到改表执行完,其它事务也就可以继续操作了,这个问题现在没办法解决,但我们长期使用下来发现,小表可以这样直接操作,大一点或者更大的,都是通过osc(pt-online-schema-change)来做,这样就很好的避免了这个问题。
挡我者死:由于Galera Cluster在执行DDL时,是Total Ordered Isolation(wsrep_OSU_method=TOI)的,所以必须要保证每个节点都是同时执行的,当然对于不是DDL的,也是Total Order的,因为每一个事务都具有同一个GTID值,DDL也不例外,而DDL涉及到的是表锁,MDL锁(Meta Data Lock),只要在执行过程中,遇到了MDL锁的冲突,所有情况下,都是DDL优先,将所有的使用到这个对象的事务,统统杀死,不管是读事务,还是写事务,被杀的事务都会报出死锁的异常,所以这也是一个Galera Cluster中,关于DDL的闻名遐迩的坑。不过这个现在确实没有办法解决,也没办法避免,不过这个的影响还算可以接受,先可以忍忍。
不死之身:继上面的“挡我者死”,如果集群真的被一个DDL卡死了,导致整个集群都动不了了,所有的写请求都Hang住了,那么可能会有人想一个妙招,说赶紧杀死,直接在每个节点上面输入kill connection_id,等等类似的操作,那么此时,很不愿意看到的信息报了出来:You are not owner of thread connection_id。
此时可能有些同学要哭了,不过这种情况下,确实没有什么好的解决方法(其实这个时候,一个故障已经发生了,一年的KPI也许已经没有了,就看敢不敢下狠手了),要不就等DDL执行完成(所有这个数据库上面的业务都处于不可服务状态),要不就将数据库直接Kill掉,快速重启,赶紧恢复一个节点提交线上服务,然后再考虑集群其它节点的数据增量的同步等,这个坑非常大,也是在Galera Cluster中,最大的一个坑,需要非常小心,避免出现这样的问题。
4. 适用场景
现在对Galera Cluster已经有了足够了解,但这样的“完美”架构,在什么场景下才可以使用呢?或者说,哪种场景又不适合使用这样的架构呢?针对它的缺点,及优点,我们可以扬其长,避其短。可以通过下面几个方面,来了解其适用场景。
数据强一致性:因为Galera Cluster,可以保证数据强一致性的,所以它更适合应用于对数据一致性和完整性要求特别高的场景,比如交易,正是因为这个特性,我们去哪儿网才会成为使用Galera Cluster的第一大户。
多点写入:这里要强调多点写入的意思,不是要支持以多点写入的方式提供服务,更重要的是,因为有了多点写入,才会使得在DBA正常维护数据库集群的时候,才会不影响到业务,做到真正的无感知,因为只要是主从复制,就不能出现多点写入,从而导致了在切换时,必然要将老节点的连接断掉,然后齐刷刷的切到新节点,这是没办法避免的,而支持了多点写入,在切换时刻允许有短暂的多点写入,从而不会影响老的连接,只需要将新连接都路由到新节点即可。这个特性,对于交易型的业务而言,也是非常渴求的。
性能:Galera Cluster,能支持到强一致性,毫无疑问,也是以牺牲性能为代价,争取了数据一致性,但要问:”性能牺牲了,会不会导致性能太差,这样的架构根本不能满足需求呢?”这里只想说的是,这是一个权衡过程,有多少业务,QPS大到Galera Cluster不能满足的?我想是不多的(当然也是有的,可以自行做一些测试),在追求非常高的极致性能情况下,也许单个的Galera Cluster集群是不能满足需求的,但毕竟是少数了,所以够用就好,Galera Cluster必然是MySQL方案中的佼佼者。
5. 总结
综上所述,Galera Cluster是一个完全可依赖的,MySQL数据一致性的绝杀利器,使用中完全不需要担心数据延迟,数据不一致的问题,DBA从此就从繁复的数据修复、解决复制延迟、维护时担心影响业务的问题中彻底解脱了。可以说Galera Cluster是DBA及业务系统的福音,也是MySQL发展的大趋势,我希望它会越来越好,也希望也有越来越多的人使用它,共同维护这个美好的大环境。
分享:MySql安装教程
1、打开下载的MySql安装文件MySql-5.7.10-win32.zip,双击解压缩,运行“Setup.exe”。勾选接收许可协议,按“Next”继续。
2、选择安装类型,有“Developer Default(开发人员默认)”、“Server only(仅服务器)”、“Client only(仅客户端)”、“Full(完全)”、“Custom(用户自定义)”三个选项,我们选择“Full”(本机开发建议选择这个),也方便了解整个安装过程。
3、检测运行环境,安装程序会自行检测系统环境,如果出现问题,按要求修改提示信息,重新检测即可,点击“NEXT”进入下一步。
4、确认执行安装以下产品,点击执行安装,此处可能需要10分钟左右,安装完成后进行配置环境。
5、软件安装完成后,出现如下的界面,这里有一个很好的功能,MySql配置向导,不用向 以前一样,自己手动配置MySql.ini了。
6、上图中进行类型和网络配置。是否启用TCP/IP连接,设定端口,如果不启用,就只能在自己的机器上访问MySql数据库了,我这里启用,把前面的勾打上,Port Number:3306,点击“Next”进入下一步配置账户和角色,这一步询问是否要修改默认Root用户(超级管理)的密码(默认为空)。
7、选择是否将MySql安装为Windows服务,还可以指定Service Name(服务标识名称),这里我们选择默认Service Name不变。按“Next”继续。
8、确认配置信息无误,如果有误,按“Back”返回检查。按“Execute”使设置生效。
9、下一步进入产品配置向导页,点击“Next”进入下一步配置默认用户名密码,这里选择默认点击下一步继续。
10、确认产品配置信息无误,如果有误,按“Back”返回检查。按“Execute”使设置生效。
11、设置完毕,按“Finish”结束MySql的安装与配置。
小结:MySQL 软件采用了双授权政策,它分为社区版和商业版,由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,一般中小型网站的开发都选择 MySQL 作为网站数据库。
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341